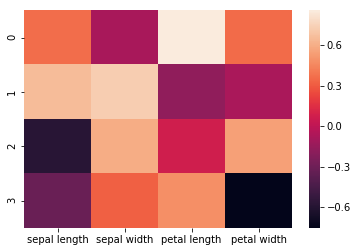1. 主成分分析Principla Component Analysis(PCA)
主成分分析是一种降维方法。主成分分析Principal component analysis(PCA)也称主分量分析,旨在利用降维的思想,把多维指标转化为少数几个综合维度,然后利用这些综合维度进行数据挖掘和学习,以代替原来利用所有维度进行挖掘学习的方法。
主成分分析的基本方法是按照一定的数学变换方法,把给定的一组相关变量(维度)通过线性变换转成另一组不相关的变量,这些新的变量按照方差依次递减的顺序排列。在数学变换中保持变量的总方差不变,使第一变量具有最大的方差,称为第一主成分,第二变量的方差次大,并且和第一变量不相关,称为第二主成分,依次类推。
2. 降维说明
假设原始数据集中有10个维度分别是tenure、cardmon、lncardmon、cardten、lncardten、wiremon、lnwiremon、wireten、lnwireten、hourstv,现在用主成分分析进行降维,降维后的每个“因子”是:
这就是主成分分析后提取的3个能代表原始10个维度的新“维度”。通过上述结果我们可以发现主成分(也就是新的“维度”)是一个线性方程,而且是多元一次的方程。PCA可以对主成分分析的结果按重要性排序并根据用户需求只选择能代表大多数(甚至全部,如果你愿意)指标意义的成分,从而达到降维从而简化模型或是进行数据压缩的效果。
3. Iris 数据集分析。
用Python的机器学习库SKlearn中的PCA来对数据进行降维。原始数据集中有4个维度,现在要通过PCA转换成2个维度。
结果如下。
PCA能找到代表原始数据最大特征的几个主成分。通过pca.explained_varianceratio可查看每个主成分能表达原始数据的方差。这里因为设置了n_components = 2,所以只能看到前两个成分的所占方差百分比,由数据可知,这两个成分的方差比例达到97%,意味着它们可以代表原始数据集95%的特征值。
PCA的应用是降维,用在所有大量数据集建模处理之前的降维过程,因此它是数据预处理过程的一步。
4. 可视化处理。
通过降维,可以把高纬度下无法做出来的图在二维或三维平面上显示出来,这也是PCA的一个非常重要的应用。
|
|
结果如图所示: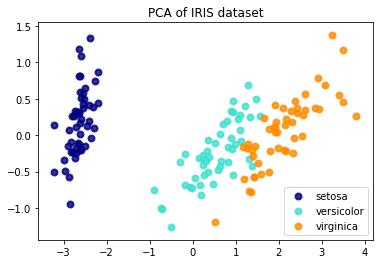
5.相关性分析。
主成分与 ‘sepal length’,’sepal width’,’petal length’,’petal width’ 这四个特征值的正负相关性可以通过pca.components_来查看。
|
|
|
|
制作heatmap图。
结果如图所示:主成分1(y轴为0)和petal length 呈强正相关,主成分2(y轴为1)和sepal lenght, sepal width呈正相关。