1. KMeans 算法
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
2. 利用iris数据进行聚类分析
导入相关库
2. 导入iris数据集并进行scale。
|
|
3. 利用模型进行聚类分析,设定分为三类。
|
|
4. 聚类可视化处理。
|
|
结果如图所示:
因为颜色不一致,稍作调整。
结果如图所示: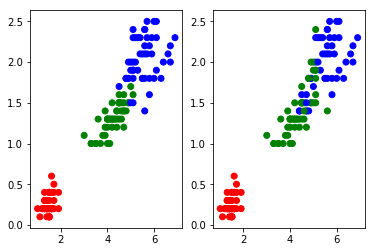
最后给出预测准确率。